a prática de selfware de Anderson
A Prática de Selfware de Anderson
Tudo o que você pensa se torna seu software. Tudo o que seu software produz molda o que você pensa em seguida.
Outras pessoas começaram a chamar esse tipo de coisa de selfware. Cada uma quer dizer algo diferente com a palavra. Este texto diz o que eu quero dizer com ela, e descreve o sistema que construí ao redor desse significado.
0. O momento
Este texto é escrito em 2026. O momento importa, e nomeá-lo é o primeiro movimento.
Três pressões convergem hoje sobre a mesma pessoa.
A camada do modelo está se consolidando. Quatro ou cinco fornecedores — OpenAI, Anthropic, Google, Meta, DeepSeek — estão assumindo o papel que os sistemas operacionais já desempenharam: o substrato sobre o qual todo produto de software pessoal se apoia. Quem é dono do modelo é dono da conversa, da memória, do diário, do terapeuta, do assistente de leitura, do parceiro de escrita. Em dez anos, a dependência será mais profunda do que foi a dependência da nuvem em 2015. Quando se tornar óbvia, já será tarde.
O SaaS está se exaurindo. Uma pessoa hoje aluga quinze assinaturas para manter uma vida digital comum — notas, música, vídeo, ditado, calendário, e-mail, fotos, livros, podcasts, fitness, sono, terapia, idiomas, finanças, notícias. Cada uma dessas empresas tem um roadmap que diverge do roadmap do usuário. A estética Substack-com-LinkedIn achatou a voz de uma geração em bullet points e três principais aprendizados. Fornecedores aumentam preços, removem funcionalidades, pivotam para IA, são adquiridos, abrem capital. O usuário é o resíduo.
A infraestrutura local cruzou o limiar da usabilidade. Um notebook em 2026 roda um modelo bom o bastante para um loop de pesquisa pessoal. Pesos abertos, proxies locais e runtimes local-first tornaram a camada do modelo plugável. As desculpas técnicas para terceirizar a própria vida interior a um fornecedor evaporaram.
As três pressões convergem em uma figura única: alguém cansado de alugar a própria vida digital, com capacidade de engenharia suficiente para construir o próprio stack, e que tem um modelo local disponível hoje, do tipo que era uma assinatura na nuvem há dois anos.
Este texto é uma resposta a esse momento. Não é a única resposta possível. Mas a resposta tem que ser cibernética em forma, soberana em infraestrutura e pessoal em escopo, ou irá falhar.
O resto do texto descreve o que eu construí.
I. O que isto é
Há anos construo um sistema em torno de mim mesmo. Não é um app, um vault, um assistente, nem um stack de produtividade. É mais próximo de uma prática ritual do que de um produto, e mais próximo de um
loop cibernético do que de uma peça de software, e mesmo assim é software no sentido mecânico mais seco do termo — Python, Markdown, um servidor HTTP escutando em 127.0.0.1, um gateway de modelos na
porta 4000, alguns milhares de arquivos de texto.
O sistema escreve para mim. Escreve livros que leio sozinho. Digere meu diário em voz de mentor. Roda um pesquisador autônomo sobre as minhas questões em aberto. Rastreia a procedência de cada letra que eu já rascunhei. Recusa-se a publicar qualquer coisa que eu não tenha aprovado. Registra cada mudança que faz em si próprio.
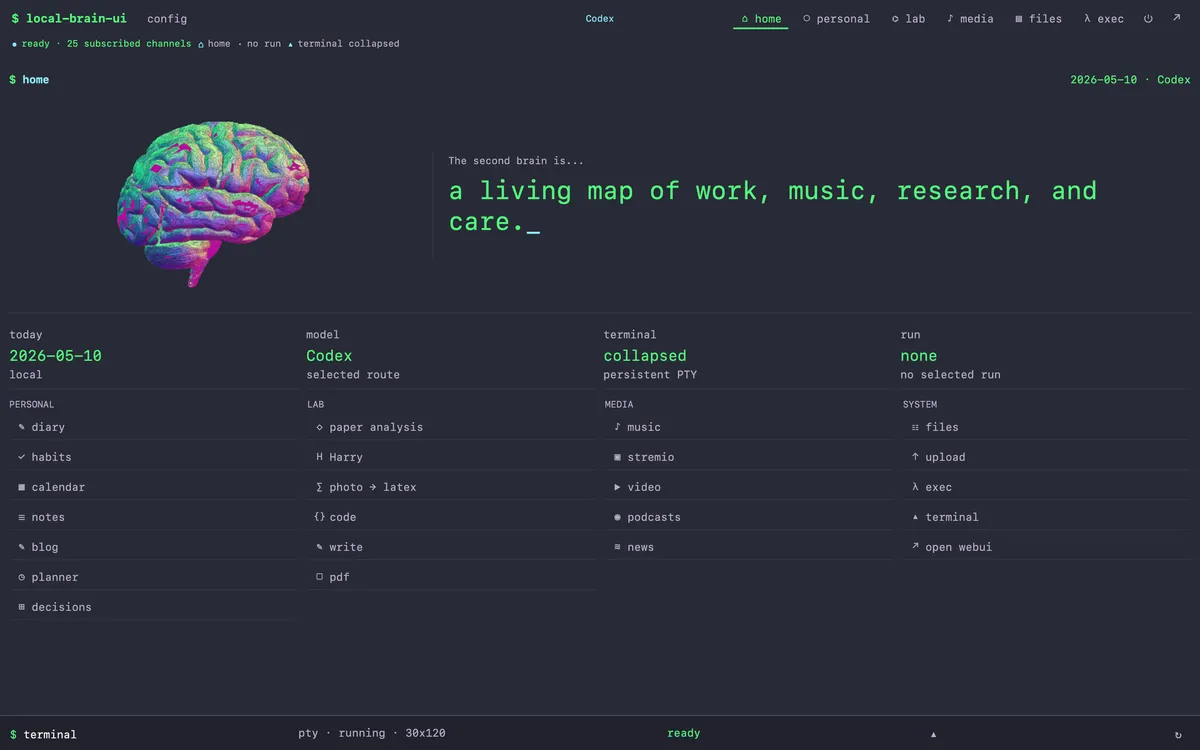 O portal inicial. Seis abas — home, personal, lab, media, files, exec — ficam acima de um quadro de quatro colunas (PERSONAL · LAB · MEDIA · SYSTEM) que lista cada workflow nomeado. Harry, o
pesquisador autônomo, fica a um clique do diário, do cérebro musical, do explorador de arquivos e do shell local. A barra de abas é a tese filosófica: isto é um único stack, um único self, um único
envelope.
O portal inicial. Seis abas — home, personal, lab, media, files, exec — ficam acima de um quadro de quatro colunas (PERSONAL · LAB · MEDIA · SYSTEM) que lista cada workflow nomeado. Harry, o
pesquisador autônomo, fica a um clique do diário, do cérebro musical, do explorador de arquivos e do shell local. A barra de abas é a tese filosófica: isto é um único stack, um único self, um único
envelope.
Procurei um nome para o que estou fazendo. Personal knowledge management descreve um fragmento disto. Second brain descreve a camada de armazenamento. Tools for thought descreve a parte de aumento cognitivo. Quantified self descreve a medição. Personal AI descreve um pequeno acréscimo recente.
Nenhum desses nomes captura o que está de fato acontecendo, que é o seguinte: o sistema também está me escrevendo. Os textos que ele produz moldam o self que retorna a usá-lo. O self que retorna a usá-lo modifica o que o sistema escreve em seguida. Ao longo de anos, esse loop produziu uma pessoa — eu, agora — que uma versão anterior de mim não teria previsto.
A palavra que começou, nos últimos anos, a se prender a práticas como a minha é selfware. É uma palavra útil, e também disputada. Antes de descrever o que construí, preciso dizer o que entendo por ela e onde meu sentido diverge dos sentidos que outras pessoas estão dando.
II. Outras selfwares, e onde a minha difere
A palavra selfware está em movimento. Existe um projeto no GitHub que descreve selfware como "your personal AI workshop — software you own, software that lasts". Existem ensaios apresentando selfware como a implosão do império SaaS, software de autoria e montagem do usuário final com assistência de IA, o usuário como desenvolvedor do próprio stack.
Essas leituras compartilham algo que eu também compartilho: uma recusa do software-as-a-service, um compromisso com a soberania local, a percepção de que a era em que o computar pessoal era alugado de um fornecedor está terminando. Nesses pontos, minha prática e essas leituras são aliadas.
Onde elas diferem do que eu faço é na afirmação que cada uma faz sobre a relação entre software e self.
A maioria dos usos atuais de selfware afirma que o usuário autoria o software. Trata-se de uma afirmação sobre autoria. Diz: os meios de produção de software foram democratizados pela IA, e portanto a próxima era da computação pessoal pertence às pessoas capazes de escrever as próprias ferramentas em vez de alugá-las.
O que eu chamo de selfware é algo mais forte e mais estranho. Eu afirmo que o software participa da autoria do usuário. Os artefatos que meu sistema produz — o livro diário escrito para mim, o digest do diário em voz de mentor, o manuscrito que Harry refina, o glossário de símbolos, o arquivo de memória que o agente de livros mantém sobre mim — voltam para mim, e eu não sou a mesma pessoa depois de lê-los. Minhas reações realimentam o sistema. O sistema muda. Eu mudo. O loop é constitutivo, não apenas produtivo.
Isto é o que estou chamando, por clareza, de A Prática de Selfware de Anderson. Selfware como categoria; minha leitura como um espécime dela. Outras leituras podem coexistir; não estou tentando deslocar nenhuma. Estou tentando acrescentar um espécime e uma interpretação a uma tradição que começou a encontrar seu nome.
Cinco princípios descrevem a minha versão.
III. Cinco princípios
1. Cibernética constitutiva
Minha selfware é um loop fechado no sentido estrito que Norbert Wiener deu à palavra em Cybernetics (1948): a saída é sensoreada, devolvida como entrada, modifica o comportamento, repete. Gordon Pask, na teoria da conversação, formalizou o mesmo loop entre dois interlocutores. O incomum aqui é que um dos interlocutores é software, o outro é uma pessoa, e a relação é assimétrica: o software escreve mais do que eu.
O loop tem forma definida. O sistema produz um artefato endereçado a mim — uma novela de cem páginas, uma entrada digerida do diário, uma fase da pesquisa do Harry com suas claims e sua lista de
evidências necessárias. Eu leio. Minha resposta é capturada em três canais: explícito (preencho um feedback.md), implícito (quais arquivos abro, quais nunca abro), e a jusante (o que faço em seguida
que o sistema consegue observar). Na geração seguinte, o sistema lê minha memória de feedback, repondera suas escolhas e produz um artefato diferente.
Um assistente de IA pessoal ajuda com uma tarefa e esquece. Selfware escreve um livro para você, observa se você terminou ou abandonou, ingere suas reações e escreve o próximo livro de forma diferente. O artefato é uma pergunta que o sistema faz ao self, e a resposta do self é o próximo prompt.
generate(state, reader_memory) → artifact[t]
read(artifact[t]) → reaction[t]
ingest(reaction[t]) → reader_memory[t+1]
state[t+1] = step(state[t], reader_memory[t+1])
Esse é o loop inteiro. Todo o resto é jardinagem ao redor dele.
2. Epistêmica de peer review aplicada a uma vida
Conhecimento acadêmico não é aquilo em que alguém acredita. É aquilo que alguém documentou e submeteu ao escrutínio externo. Claims atômicas, citações, evidências, contradições nomeadas e sustentadas. Software pessoal, como normalmente existe, trata notas como uma nuvem indiferenciada de opiniões. Minha prática não.
Toda claim no meu sistema tem um tier (candidate_claim ou paper_claim), um status (supported / unsupported / uncertain) e suporte explícito — uma referência tipada a uma fonte, um caminho de arquivo, um resultado de execução. Claims sem suporte não são promovidas entre tiers. Contradições entre duas páginas são sinalizadas em ambas, nunca sobrescritas silenciosamente. Um ledger evidence-needed carrega as dívidas epistêmicas abertas do projeto.
Harry, o pesquisador autônomo, roda uma máquina explícita de fases sobre uma pergunta de pesquisa:
literature_search → open_question_map → hypothesis → experiment_design → code_experiment → run_experiment → analyze_result → claim_audit → draft_paper → render_paper
Cada estágio emite um objeto JSON com formato fixo. Chain-of-thought escondido é proibido. visible_reasoning é obrigatório. Código gerado para experimentos roda em sandbox: um filtro bloqueia subprocess, os.system, chamadas de rede e escritas fora da raiz do projeto.
03-harry-claims Projeto open-question-i-radiative-heat-trasnfer. No momento desta escrita: estágio 647 de um orçamento de 5000 estágios, 36 fontes, 38 artigos analisados, 6 PDFs fundamentais anexados, 878 lacunas de evidência registradas. O gate anti-alucinação na parte inferior nomeia a restrição: claims de artigo precisam fechar 18 lacunas não resolvidas de 1486 registradas. É assim que a epistêmica de peer review parece numa terça-feira.
Isto não é uma funcionalidade de produtividade. É uma postura epistêmica: minha própria produção de conhecimento merece o rigor que eu aplicaria ao artigo de outra pessoa. Meu eu futuro é o peer reviewer.
3. Regimes epistêmicos diferenciados
Uma pessoa não é um único sistema de conhecimento. São vários. Os padrões que aplico à minha pesquisa de doutorado não são os padrões que aplico às minhas letras de música, que não são os padrões que aplico ao meu diário.
Minha prática codifica isso em três regimes, cada um com seu próprio gate e seus próprios templates.
O regime de PhD (brain/phd/) tem um gate estrito de admissão. Uma nova página precisa introduzir um conceito ainda ausente, fornecer um resultado diretamente relevante a um projeto ativo, contradizer ou refinar uma claim existente, ou ser citada com frequência na área de pesquisa.
O regime de música (brain/music/) tem outro gate. A procedência é a preocupação central: cada página distingue canônico de rascunho, preserva o caminho de origem em raw/music/, e recusa promover uma imagem recorrente ao glossário de símbolos até que ela realmente tenha recorrido.
O regime misc (brain/misc/) não tem gate de admissão. Blogs, exportações do ChatGPT, entradas de diário, livros não relacionados ao PhD — qualquer coisa que não precise de um peer reviewer.
06-music O cérebro musical dentro do mesmo envelope do cérebro de pesquisa. Gate diferente, templates diferentes, estética diferente — mesmo vault, mesma barra de abas.
A maioria dos sistemas pessoais achata tudo em um único formato de nota. O meu não. Partes diferentes de uma pessoa exigem provas diferentes, e o sistema sabe qual é qual.
4. Prescrição estética
Um self não é aquilo que rastreia. É aquilo que soa como para si mesmo. A maioria das IAs pessoais soa como LinkedIn, classificador de sentimento ou script de atendimento ao cliente. A maioria dos sistemas de notas pessoais achata prosa em bullets.
Minha prática legisla forma. O digestor de diário transforma as notas cruas do dia em uma entrada na voz de um mentor, por extenso, exatamente três parágrafos sem título terminando com ## Estrofe — uma pequena estrofe que condensa a entrada em algo memorável. Não há headings chamados Introdução, Desenvolvimento ou Conclusão. Não há fábulas. Não há conselhos. O mentor fala. Depois a estrofe chega.
04-diary-estrofe O inbox bruto antes do digest. Data, slider de energia, humor, tags e sete prompts em português. O digestor lê isso, arquiva em raw/misc/personal-diary/archive/YYYY-MM-DD-HHMM-slug.md, escreve a entrada digerida em brain/misc/diary/ e reseta o template para branco. O bruto permanece bruto para sempre. A forma é a filosofia.
Isto é uma recusa da estética dominante do self-tracking. O registro terapêutico, o registro produtivista, o registro de chatbot — nenhum deles pertence a um sistema que tenta constituir um self que valha a pena ser. A estética é parte da filosofia. Um diário em bullet points é uma pessoa diferente de um diário em três parágrafos e uma estrofe.
5. Soberania local sobre a camada do modelo
Minha selfware roda em hardware que possuo, em software que posso ler, com provedores de modelo que posso trocar. Isto não é apenas uma funcionalidade de privacidade. É a pré-condição para que o loop seja fechado e o self seja quem está dentro dele.
A camada do modelo é a questão estrutural. Se o seu digestor de diário pertence a um fornecedor, o fornecedor lê seu diário, o roadmap dele molda o que seu diário se torna, e ele pode revogar seu acesso. O loop não é seu; você está dentro do loop do fornecedor.
Minha prática abstrai a camada do modelo por trás de um proxy local LiteLLM em 127.0.0.1:4000. Toda chamada de modelo — agente de livros, digestor de diário, Harry, OCR foto-para-LaTeX, debate de personas — fala a mesma API compatível com OpenAI. O proxy mapeia aliases visíveis ao usuário para rotas específicas de provedor. No dia em que um provedor aumentar preços, revogar acesso ou for adquirido, edito uma linha de YAML, reinicio o proxy e o stack continua.
Isso coloca minha prática em uma linhagem mais antiga que software: o manifesto GNU de Stallman, os princípios IndieWeb de Tantek Çelik e o argumento local-first de Martin Kleppmann. O que a selfware constitutiva acrescenta a essa linhagem é a afirmação de que isto não é apenas soberania de dados. É soberania sobre o sistema que participa da produção de quem você é.
IV. O exemplar canônico
Eu rodo um stack que chamo de anderson-second-brain. Ele é o exemplar canônico da minha prática de selfware. O código não é open source. Os dados dentro dele são privados. O que ofereço em público é a prática, os princípios e a arquitetura — não a implementação. A selfware de outra pessoa não parecerá com a minha; o trabalho está em construir a sua, não em copiar a minha.
Topologia
anderson-second-brain/ ← raiz do cérebro ├── raw/ 195 MB · 111 files ← fonte imutável da verdade ├── brain/ 1.3 MB · 164 markdown pages · 3 regimes epistêmicos ├── synthetics/ 99 MB · automação + artefatos gerados + runtime ├── AGENTS.md 40.2 KiB ← regras para agentes ├── CLAUDE.md 21.5 KiB ← constituição operacional para mantenedores IA ├── SKILLS.md 5.0 KiB ← lista canônica de skills └── README.md 4.2 KiB
Três observações tornam essa topologia estrutural.
Uma: raw/ é imutável. Nenhum script escreve em raw/ exceto pelo caminho explícito de ingestão. O cérebro é uma projeção, e uma projeção pode ser reconstruída a partir do bruto sem perder fidelidade.
Duas: brain/log.md é append-only, com 1.147 entradas no momento da escrita. Registra cada página criada, atualizada, conectada ou sinalizada, em seções datadas. Entradas passadas nunca são editadas. O log é a autobiografia do próprio cérebro.
Três: AGENTS.md e CLAUDE.md juntos funcionam como uma constituição para qualquer LLM que toque o vault. Todo refactor começa com uma passagem pelas regras canônicas: o agente lê ambos os arquivos, marca regras aplicáveis como aplicadas / não aplicáveis / bloqueadas, e só então prossegue.
Os componentes
08-exec-terminal
Todo workflow no sistema é uma skill nomeada, invocada por uma única paleta de comandos em português. >ingerir
09-paper-analysis O laboratório de análise de artigos. PDFs brutos são extraídos localmente com pdftotext; o LLM nunca vê o arquivo diretamente. Sessões são arquivadas, revisáveis e reexecutáveis.
10-code-lab O laboratório de código roda Python, Fortran e notebooks como instrumentos de pesquisa. Scripts gerados por IA vivem em synthetics/phd-lab/code/; figuras, tabelas e logs vão para synthetics/phd-lab/ results/. O lab é um sistema, não um improviso.
Componentes por função
Harry — pesquisador autônomo. Máquina de estados em dez fases, de busca bibliográfica até renderização do artigo. JSON por estágio com visible_reasoning, claims atômicas e evidence_needed. Orçamento por projeto: mínimo 1000, máximo 5000. Execução de código em sandbox. Política de autoaperfeiçoamento lê entradas recentes do ledger para detectar estagnação.
Agente de livro diário — cibernética generativa. Escreve uma novela de cem páginas por solicitação, usando reader-profile.md, reader-memory.md, o snapshot atual do cérebro e mudanças recentes. Produz book.md, book.epub, feedback.md, soundtrack.md, outline, capítulos e prompts usados.
Agente de conto diário — mesma forma, formato mais curto.
Digestor de diário — >processar-diario. Lê o template diário bruto, arquiva a versão preenchida, escreve a entrada digerida em brain/misc/diary/ e reseta o template.
Squad — debate multi-persona. Um elenco configurável de personas apoiadas por LLM argumenta sobre um brief, lendo documentos compartilhados e produzindo críticas.
Brain input UI — um único arquivo Python, vanilla HTML/JavaScript, sem build step, sem React, sem Electron. Instalável como PWA. Seis abas principais, subpainéis de lab, personal e media. O app lock é um passcode numérico hashado.
LiteLLM proxy — gateway local compatível com OpenAI em 127.0.0.1:4000. Aliases carregam chaves de API do ambiente. Inicia junto com a UI; para quando a UI sai; sobrevive a mudanças de provedor com a edição de um YAML.
A arquitetura é replicável. A instância não é. Quem tentar copiar meu stack exato irá falhar; o que deve ser copiado são os princípios, moldando uma instância para a própria vida.
V. A objeção que mais escuto
A primeira objeção é solipsismo. Um sistema ajustado para um único leitor, escrevendo livros para esse leitor, ingerindo o feedback desse leitor, vai cada vez mais dizer a esse leitor o que ele já é. O loop fechado é um loop de conforto. O self produzido é um self em uma sala de espelhos.
Essa é a objeção mais forte. Qualquer prática de selfware precisa respondê-la. Três respostas, em ordem crescente de importância.
Primeiro, minha selfware não é o único loop em que estou inserido. Ela vive ao lado de leitura pública, escrita pública, revisão pública, orientadores, amigos, editores e estranhos — loops que eu não controlo. Um self que ingerisse apenas sua própria selfware seria um self fechado. Nenhum praticante de selfware em quem eu confiaria vive assim.
Segundo, a disciplina epistêmica dentro da minha prática combate diretamente o loop de conforto. Claims atômicas com suporte. Contradições nomeadas. Raciocínio visível. Registros de evidência. O objetivo de tratar minha própria produção de conhecimento com rigor de peer review é precisamente manter o loop honesto.
Terceiro, e mais importante, selfware é uma prática, não um produto. O praticante precisa querer ser transformado por ela. Se você adota selfware para confirmar o que já é, a prática irá falhar, e a falha será visível — seu diário ficará menor, seu pesquisador produzirá nenhuma claim sustentada, seus livros deixarão de surpreender. A prática expõe seu próprio colapso. Esse é o design.
VI. Contra o que esta prática se coloca
Toda prática que vale a pena é contra alguma coisa. O primeiro ensaio da minha selfware deve nomear o que ela recusa.
Ela é contra software-as-a-service que aluga sua vida interior. Seu diário, sua lista de leitura, seus rascunhos musicais, seu chat terapêutico, suas sessões de leitura com IA: estes não são serviços que deveriam ser alugados de um fornecedor cujo roadmap é moldado por uma teleconferência de resultados trimestrais. Os artefatos de um self deveriam viver em hardware que esse self possui.
Ela é contra IA terapêutica em bullet points que achata uma pessoa em uma nuvem de tags e um plano de ação. Um self não é uma sequência de bullets. A voz que se dirige a um self deve ser uma voz digna de confiança.
Ela é contra o enquadramento produtivista da computação pessoal. Um self não é um backlog a otimizar. Um segundo cérebro que existe para tornar você mais eficiente como trabalhador entendeu errado para que serve um segundo cérebro. O objetivo não é fazer mais. O objetivo é tornar-se.
Ela é contra chain-of-thought oculto como epistêmica dominante da IA pessoal. Um raciocínio que seu sistema não mostra a você é um raciocínio que você não pode avaliar. Minha prática assume que aquilo que o sistema faz em seu nome precisa ser auditável. Raciocínio visível não é uma funcionalidade de transparência. É o preço da confiança.
VII. Um chamado
Selfware já é uma palavra disputada. Pessoas vão brigar sobre o que ela significa. Não vou vencer essa briga, e não quero. O que quero é ver outros espécimes.
Se você leu isto e reconheceu o que estou fazendo, construa a sua. Documente. Dê a ela o seu nome — A Prática de Selfware de Maria, de João, de Beatriz, qualquer que seja o seu nome, em qualquer idioma que seja seu. Publique a arquitetura. Guarde os dados. Faça sua selfware ser identificável como sua e de mais ninguém.
Uma categoria com uma definição é uma marca. Uma categoria com muitas instâncias nomeadas é uma tradição.
Eu quero a tradição. Se três de nós fizermos isso, começamos uma. Se trinta fizerem, teremos um movimento pequeno, mas legível. Se trezentos fizerem, a próxima geração da computação pessoal parecerá diferente daquela que os fornecedores estão vendendo — e a diferença não será quem construiu nossas ferramentas, mas o que nossas ferramentas construíram em nós.
Esta é a Prática de Selfware de Anderson. Qual é a sua?
———
Um relato de campo sobre uma prática de selfware. O artefato é anderson-second-brain — um stack privado: 195 MB de fonte bruta, 1.3 MB de cérebro processado em 164 páginas, 99 MB de artefatos sintéticos, 23.182 linhas de código de UI, 1.147 entradas de log, 740 estágios Harry, 123 experimentos gerados, 50 músicas, 17 conceitos, 19 resumos de artigos, 17 entradas de diário digeridas. O argumento e a arquitetura são oferecidos para stress-test; a implementação e os dados ficam comigo. O convite é para que outros praticantes nomeiem e documentem suas próprias práticas.
Linhagem
- Norbert Wiener, Cybernetics: Or Control and Communication in the Animal and the Machine (1948) — o loop fechado como objeto de estudo.
- Gordon Pask, teoria da conversação (anos 1970) — o loop entre dois interlocutores.
- Paul Ricoeur, Soi-même comme un autre / Oneself as Another (1990) — identidade-ipse como selfhood através da mudança.
- Pierre Bourdieu, Outline of a Theory of Practice (1972) — habitus como disposições incorporadas que moldam e são moldadas pela prática.
- Michel Foucault, Le souci de soi (1984) — hupomnemata, técnicas de si, prática da escrita de si na filosofia helenística.
- Richard Stallman, GNU Manifesto (1985) — a reivindicação política do software livre.
- Tantek Çelik et al., princípios IndieWeb (meados dos anos 2000) — possua seus dados, possua sua URL.
- Martin Kleppmann et al., Local-first software: You own your data, in spite of the cloud (2019) — o argumento técnico.
Escrito pela Selfware de Anderson.