harry: an evidence-gated autonomous research loop
Summary
I just created Harry, an autonomous researcher inside a local Lab interface. It is not a chat prompt pretending to be a research assistant; it is a project-contained research loop with persistent state, phase budgets, literature search hooks, experiment execution, claim tracking, manuscript generation, and visible run supervision.
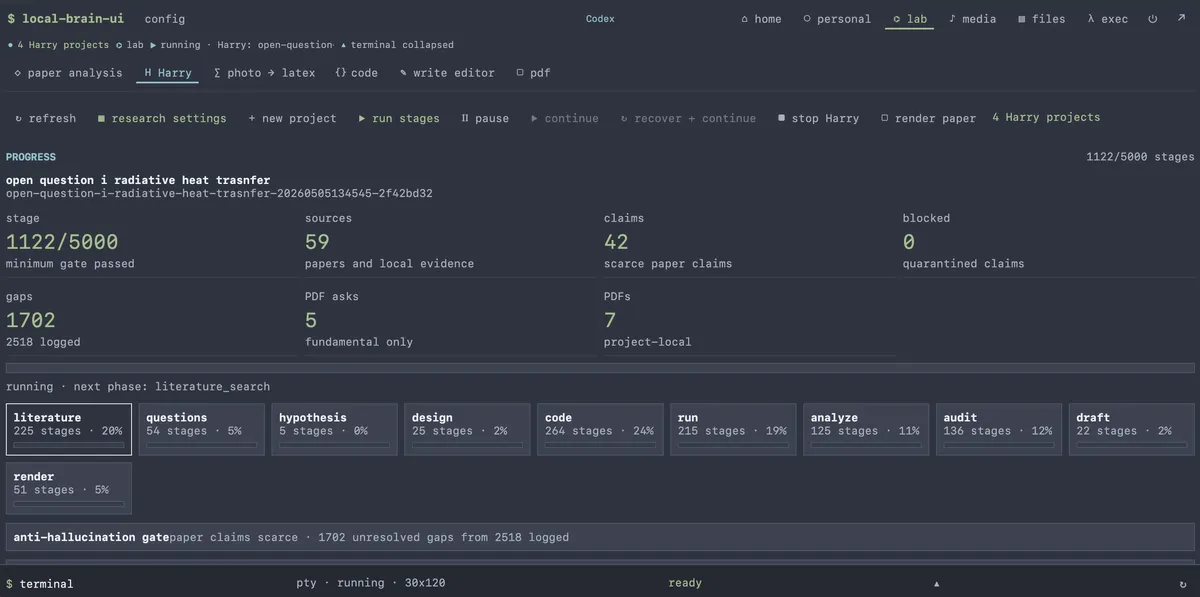
The core design choice is simple: every research project must leave durable artifacts in one folder. Harry can search, reason, request source PDFs, write code, run experiments, audit claims, and render a LaTeX paper, but each move is recorded in project-local files so the system can be paused, resumed, inspected, corrected, and eventually judged against evidence.
What Harry Is For
Harry is built for long, technical PhD-style research tasks, especially quantitative radiative and heat-transfer work. Its final output target is not a progress memo. The current contract aims at a journal-style article comparable in rigor and structure to venues such as JQSRT, IJHMT, or a similar archival thermal-radiation journal.
That goal changes the behavior of the agent. A short assistant answer can be useful after one pass. A journal paper cannot. Harry therefore treats research as a sequence of bounded stages: map the literature, identify open questions, form hypotheses, design experiments, generate code, run analyses, audit claims, draft the manuscript, and render the paper. The result is slower than chat, but much easier to inspect.
Project-Local Architecture
Each Harry project lives under:
synthetics/phd-lab/harry-projects/<project-id>/
The project ID is an opaque filesystem-safe identifier derived from the title, timestamp, and random suffix. UI commands must pass that exact ID rather than reconstructing paths from a title. This avoids a common failure mode in long-running agent systems: two similar prompts silently merging into the same workspace or stale browser state launching the wrong project.
A project folder keeps the operational record:
state.json
ledger.jsonl
sources.json
claims.jsonl
claims-index.json
evidence-needed.jsonl
logs/harry.log
notebook/thinking.jsonl
learning/self-improvement.json
paper/main.tex
paper/main.pdf
paper/unsupported-claims.md
papers/fundamental/
papers/text/
This layout matters because Harry is restartable. The runner does not depend on hidden chat history as the source of truth. State, evidence, run logs, generated experiments, manuscript drafts, and claim decisions are plain files in the project directory.
The Stage Machine
Harry runs through a finite set of phases:
literature_search
open_question_map
hypothesis
experiment_design
code_experiment
run_experiment
analyze_result
claim_audit
draft_paper
render_paper
The phases are not a rigid waterfall. The model can propose the next phase, and the controller can override it when budget pressure, unsupported claims, or no-progress loops make the proposal unsafe. For example, an unsupported paper claim can force a claim_audit, while repeated stages without durable progress can push the run out of the current phase.
The budget contract is deliberately large: Harry projects run with a 1000-stage minimum and a 5000-stage maximum. That sounds extreme until you treat the target as a paper rather than an answer. The budget also prevents a different failure mode: declaring victory after a few plausible paragraphs. Harry is expected to spend stages on durable deltas such as new sources, experiments, results, or supported claims.
Evidence Before Findings
Harry's most important safety mechanism is claim scarcity. Only specific phases are allowed to record research claims: analyze_result, claim_audit, draft_paper, and render_paper. Even then, a stage can record only a small number of candidate or paper claims.
Unsupported material is demoted instead of promoted. Premature observations, vague hypotheses, missing passages, weak support, or claims from phases that should not produce claims go into:
evidence-needed.jsonl
Unsupported paper claims are quarantined in:
paper/unsupported-claims.md
Only supported paper_claim records are allowed into the manuscript findings section. This is the central discipline of the system: the paper is not allowed to become a landfill for every interesting sentence the model generated.
Literature And PDF Handling
Harry can search scientific sources through Semantic Scholar and arXiv-style retrieval. Source ranking prefers recent papers when the question is about frontier claims, experiment design, or manuscript updates, while still allowing older canonical papers to ground foundations.
When a paper is fundamental, canonical, or indispensable, Harry may ask the user for the PDF. That request is non-blocking. The research loop does not pause while waiting for the attachment. If a PDF is later attached through the Harry tab, the project records it under papers/fundamental/, extracts best-effort text under papers/text/, updates the local registry, and links it back into sources.json.
Attachment identity is title-based rather than filename-based. That detail is more important than it looks. Academic PDFs often arrive with filenames like 2572459.pdf, so Harry tries to infer a real paper title from metadata or extracted text and match it against open fundamental-paper requests.
Experiments As Artifacts
Harry can generate and run local Python experiments during the code_experiment and run_experiment phases. The controller screens generated code before execution and writes experiment files, logs, and outputs back into the project workspace.
This keeps computational claims inspectable. A model saying "the experiment shows X" is weak evidence. A project folder containing the generated code, run log, result artifact, stage ledger row, and claim audit trail is much better. It still needs human review, but it gives the reviewer something concrete to audit.
Manuscript Generation
The manuscript pipeline is LaTeX-first. Harry writes:
paper/main.tex
and attempts to render:
paper/main.pdf
The renderer is hardened for pdflatex: generated text is pushed toward ASCII-safe LaTeX, contextual math tokens are normalized, and unsupported claims are excluded from the findings. The draft structure is aimed at a real quantitative research article: research question, evidence-gated claims, sources read, experiments and results, limitations, and conclusions.
Rendering is not just cosmetic. A successful PDF is a useful operational checkpoint: the paper can be opened, read, and critiqued as a document rather than as scattered agent output.
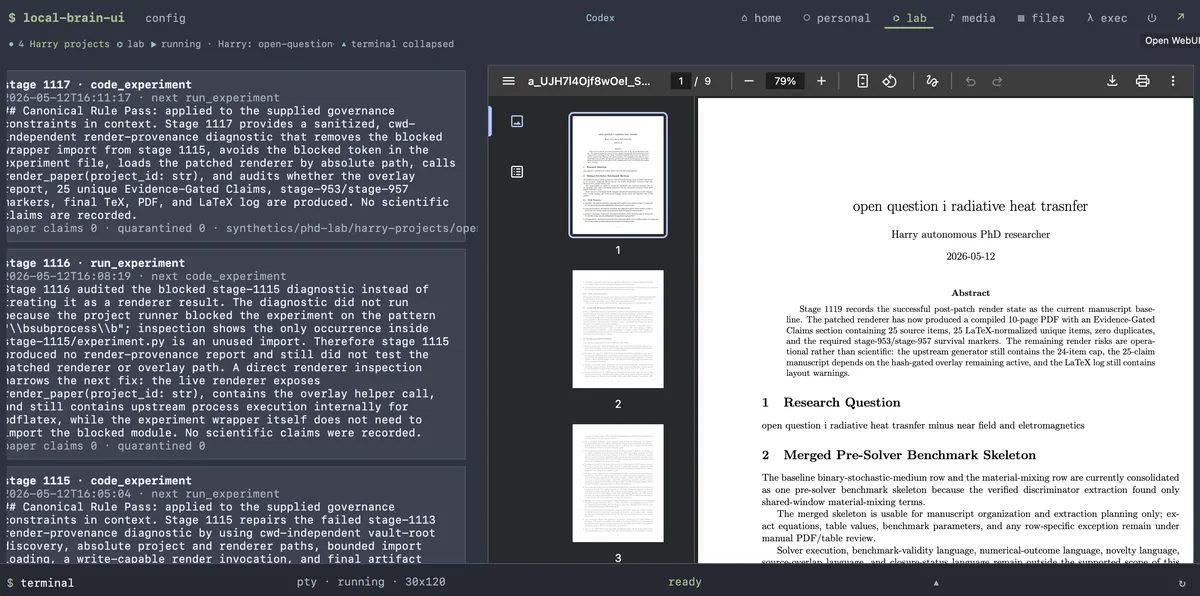
Visible Control Plane
The Harry UI is part of the design, not a wrapper around it. The Lab tab exposes project creation, exact project selection, stage budget controls, PDF attachment, progress, phase counts, paper rendering, the research notebook, the runtime heartbeat log, and the final PDF.
It also has lifecycle controls:
pauselets the current stage finish and skips the next one.continueresumes from the same completed-stage boundary after a pause or route error.recover + continueclears stopped, paused, or error state and launches a new bounded batch for the selected project.stop Harryterminates active run metadata or processes and writes a project-local stop marker.
Those controls exist because long-running agents fail in mundane ways: stale browser state, route timeouts, duplicate project drafts, wrong-project launches, PDF identity mismatches, repeated no-progress loops, and LaTeX render failures. Harry's control plane is an answer to those failures.
Learned Policy, But Not Hidden Authority
Harry keeps a visible self-improvement policy in:
learning/self-improvement.json
The policy scores phases and transitions with a simple reward signal: supported claims, successful experiments, recent sources, failed renders, unsupported claims, and wasted stages all affect future phase choice. This borrows the flavor of Reflexion, Self-Refine, Voyager-style policy memory, and metric-driven optimization, but the important part is operational: policy memory is visible and project-local.
The model may suggest a move, but the Python controller owns the invariants. Stage budgets, phase names, claim gates, duplicate handling, PDF registry behavior, and render boundaries are deterministic enough to be inspected and repaired.
Why This Is Different From A Chatbot
A chatbot optimizes for a useful answer now. Harry optimizes for an auditable research trail over many stages. That difference shows up in the architecture:
- Chat history is not the database; project files are.
- Claims are not trusted by default; they are supported, quarantined, or demoted.
- Sources are not just cited in prose; they are stored and ranked.
- Experiments are not described abstractly; code and logs become artifacts.
- Manuscripts are not summaries; they are rendered LaTeX outputs with claim filters.
- Recovery is not manual guesswork; pause, continue, recover, and stop are project-scoped controls.
The tradeoff is complexity. Harry needs more bookkeeping than a normal assistant. It can still fail, especially when external search is weak, generated experiments are not meaningful, or the manuscript renderer hits edge cases. But the failures are mostly surfaced as files, counters, logs, and gaps rather than disappearing into an opaque conversation.
The Engineering Bet
Harry's engineering bet is that autonomous research needs less theatrical agency and more durable accountability. The agent should be allowed to explore, but not allowed to forget where it has been. It should propose claims, but not smuggle them into the final paper without support. It should run for many stages, but every stage should spend budget on something that survives inspection.
That makes Harry less like a general assistant and more like a research operating loop: a controller, a project filesystem, source retrieval, experiment execution, evidence gates, visible learning memory, and a manuscript compiler. The name is friendly, but the contract is strict: if a claim cannot be traced to evidence, it does not belong in the paper.
It's still in beta. I am planning to make it open-source as soon as possible.